SwanLake:一个基于 DuckDB + DuckLake 的 Arrow Flight SQL 数据湖服务
2023 年我把 duckdb-rs 交给 DuckDB 官方维护之后,心里一直有个没做完的题:
如果 DuckDB 在单机进程里已经足够强,那怎么把这份能力变成一个更容易接入、可部署、可观测的服务?
SwanLake 就是我给这个问题的答案。
它本质上是一个基于 Rust 的 Arrow Flight SQL Server,底层执行引擎是 DuckDB,同时围绕 DuckLake 做了数据湖场景的能力扩展。更准确地说,SwanLake 的核心组合是 DuckDB + DuckLake + Arrow Flight SQL。
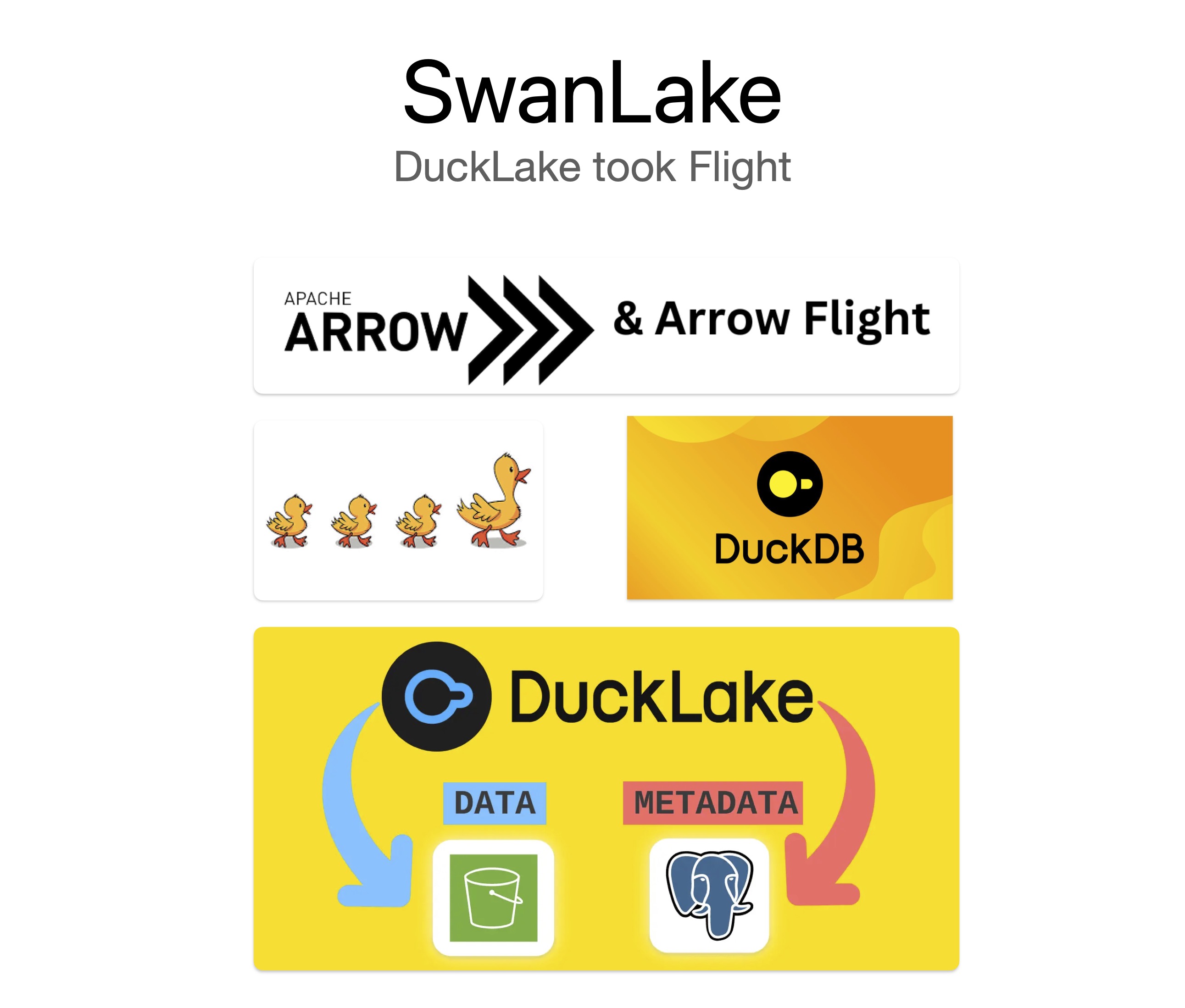
为什么是 SwanLake⌗
我最早做 duckdb-rs 的时候,目标是把 DuckDB 更自然地带到 Rust 生态里。这个目标后来基本实现了,但新的问题也很明确:
- 很多团队不是 Rust 单一语言栈,客户端接入方式需要统一。
- 业务里常见的不只是“本地查询”,而是对象存储 + 元数据 + 多服务协作。
- 线上系统需要可观测性,不能只靠日志排障。
所以 SwanLake 从一开始就不是“再封一层 API”,而是想做一个可以真正放进生产系统的分析服务入口。
系统架构⌗
SwanLake 可以按 5 层来理解:
1) 接入层:Arrow Flight SQL(gRPC)⌗
服务对外暴露 Flight SQL 接口,查询和更新请求都从这里进入。这个协议的核心价值是跨语言和高吞吐,仓库里的 Rust/Go/Python 示例就是围绕这层展开的。
2) 会话层:Session Registry⌗
swanlake-core 里有连接级会话管理:
- 按
peer_addr或peer_ip生成/复用会话 ID。 - prepared statement、事务、临时对象都跟随会话。
- 通过最大会话数和空闲超时做资源保护。
3) 执行层:DuckDB⌗
执行层没有重新造轮子,而是把 DuckDB 封装成服务可用的执行引擎。每个会话持有独立连接,启动时会加载 ducklake/httpfs/aws/postgres 扩展,并支持通过 SWANLAKE_DUCKLAKE_INIT_SQL 注入初始化 SQL。
4) 数据湖层:DuckLake⌗
DuckLake 是这个系统最关键的一层。没有 DuckLake,DuckDB 更多是本地分析引擎;有了 DuckLake,元数据和对象存储路径就能以统一方式组织起来,SwanLake 才能把“DuckDB 做数据湖”变成可部署的服务方案。
5) 运维层:Metrics + Status + 配置⌗
运行时指标(延迟、慢查询、错误)、状态页(/ + status.json)和环境变量配置(SWANLAKE_*)共同组成了运维面。这个层的目标是让系统上线后可观测、可调优、可回滚。
可观测性⌗
SwanLake 内置了状态页(默认 :4215)和 status.json,会展示:
- 当前会话数、空闲时长等会话状态。
- Query/Update 延迟统计(平均、P95、P99)。
- 慢查询和最近错误。
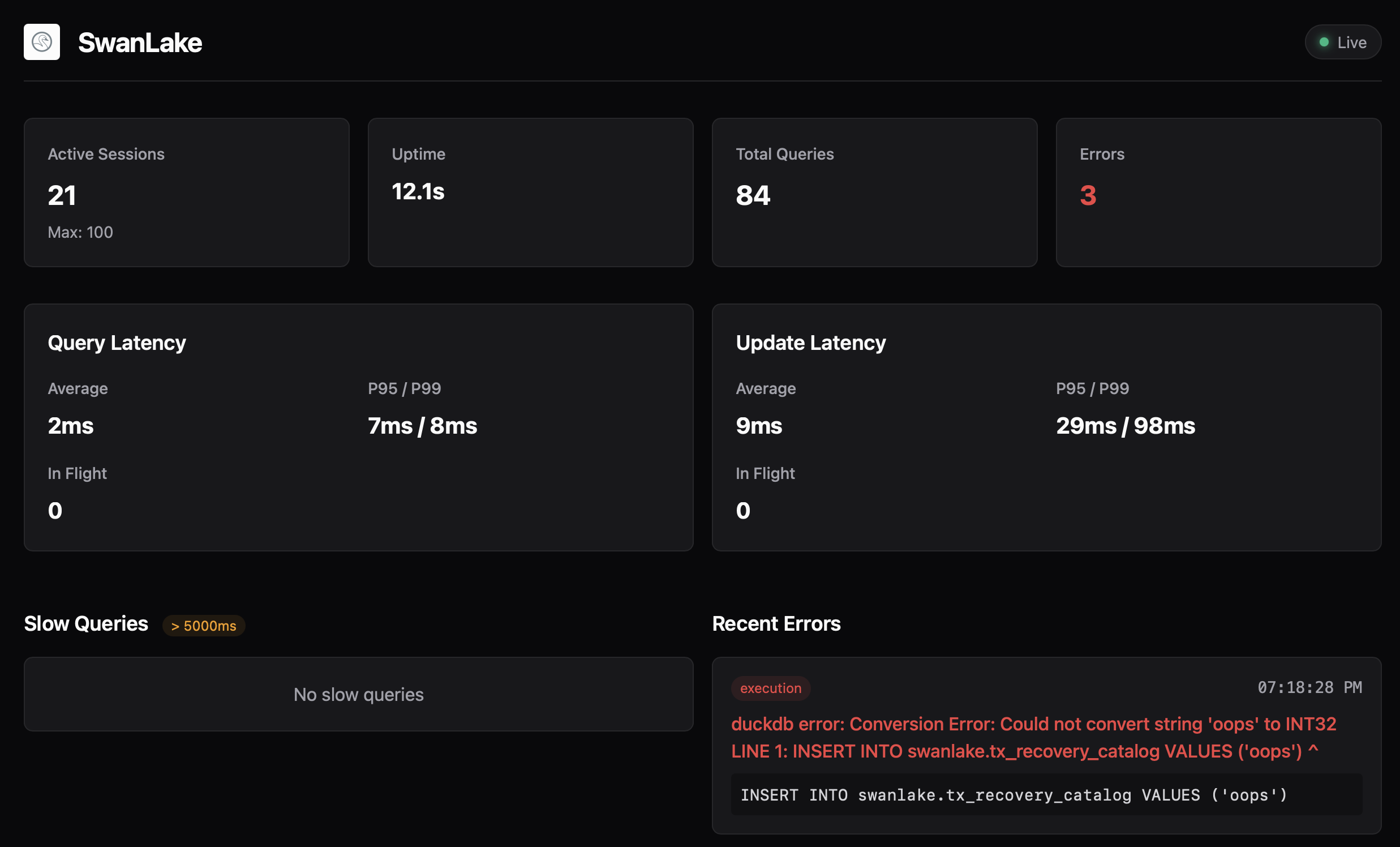
我做这个页面不是为了“好看”,而是因为这正是我自己排查问题时最想第一时间看到的数据。
当前 benchmark,我怎么看⌗
仓库里的 BENCHMARK.md(2026-02-21)有一组 TPCH(SF=0.1)结果:postgres_local_file 相比 postgres_s3 在这轮测试里更快。
| 指标(SF=0.1) | postgres_local_file | postgres_s3 |
|---|---|---|
| Throughput (req/s) | 10.428 | 4.867 |
| Avg latency (ms) | 382.751 | 818.041 |
| p95 latency (ms) | 829.236 | 1904.023 |
| p99 latency (ms) | 1116.002 | 2661.619 |
这个结果在预期之内:对象存储链路会引入更高的不确定性。
另外这里有一个非常重要的实践建议:如果后端是 S3 或其他远程对象存储,建议默认启用 cache_httpfs,否则延迟(尤其 tail latency)会非常不稳定。
这个策略我已经放进项目基准流程里了,具体可以直接看 .github/workflows/performance.yml:
postgres_s3默认BENCHBASE_ENABLE_CACHE_HTTPFS=true。postgres_local_file默认BENCHBASE_ENABLE_CACHE_HTTPFS=false。- 也可以通过 workflow input 显式覆盖该参数。
但我不想把它简单总结成“本地一定更好”。更准确的结论是:
- 你需要根据 workload 做分层(热数据、本地缓存、远端对象存储)。
- 你需要反复跑 benchmark 看方差,而不是拿一次结果定架构。
- 你需要把指标做成持续可见的数据,而不是一次性报告。
从 duckdb-rs 到 SwanLake⌗
如果说 duckdb-rs 解决的是“如何让开发者在 Rust 里优雅地用 DuckDB”,那 SwanLake 解决的是另一个问题:
如何把 DuckDB 变成一个团队可共享的、可部署的、可运维的数据服务。
这两个项目对我来说是一条连续的技术路线,而不是两个孤立项目。
后面还会做什么⌗
SwanLake 还在持续迭代,我接下来会继续重点做几件事:
- 继续补齐生产场景下的稳定性与压测数据。
- 优化对象存储场景的性能和可预测性。
- 让客户端和服务端的使用体验更统一,降低接入门槛。
如果你之前用过 duckdb-rs,我也很欢迎你来试试 SwanLake,提 issue、提 PR、或者直接分享你遇到的问题。