SwanLake: An Arrow Flight SQL Datalake Service Built on DuckDB + DuckLake
After handing duckdb-rs over to the DuckDB team in 2023, one question kept coming back to me:
If DuckDB is already great in-process, how do we turn that power into a service that is easier to integrate, deploy, and operate?
SwanLake is my answer to that question.
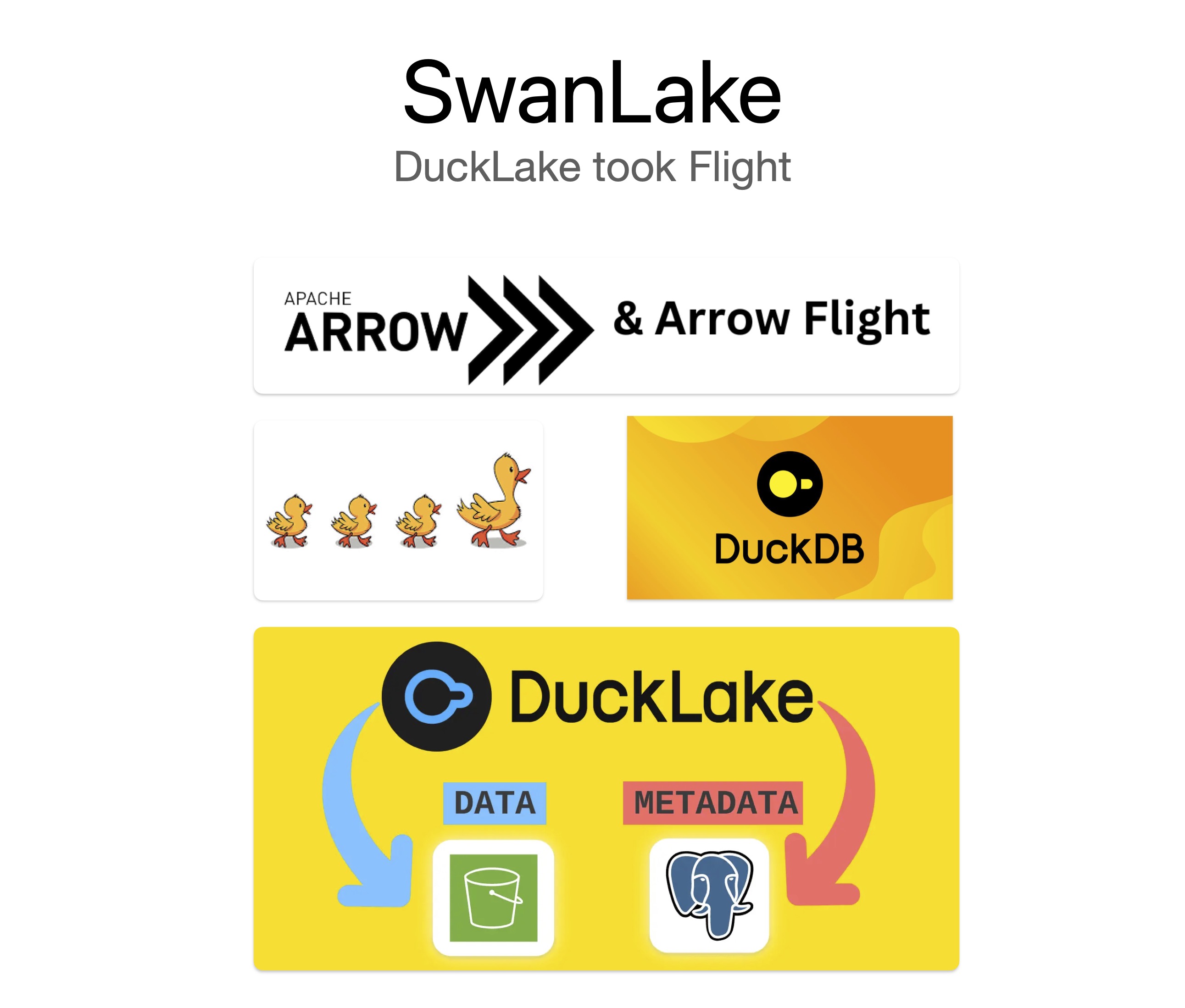
It is a Rust-based Arrow Flight SQL server, powered by DuckDB, with DuckLake-oriented extensions for datalake scenarios. In practice, SwanLake is built around a three-part combination: DuckDB + DuckLake + Flight SQL.
Why I started SwanLake⌗
With duckdb-rs, the primary goal was clear: make DuckDB feel natural in Rust. That part worked well, but new constraints became obvious:
- Most teams are not single-language; they need one service interface across stacks.
- Real workloads involve object storage, metadata services, and multiple cooperating systems.
- Production systems need observability, not just logs.
So SwanLake was never “just another wrapper”. I wanted a practical analytics service entrypoint.
Architecture⌗
You can read SwanLake as a five-layer system:
1) Access Layer: Arrow Flight SQL (gRPC)⌗
All query/update traffic enters through Flight SQL. This gives us a protocol that is efficient and language-neutral; the Rust/Go/Python examples in the repo validate this layer directly.
2) Session Layer: Session Registry⌗
swanlake-core manages connection-scoped sessions:
- session IDs are created/reused from
peer_addrorpeer_ip, - prepared statements, transactions, and temp objects remain session-affine,
- max sessions + idle timeout protect server resources.
3) Execution Layer: DuckDB⌗
I did not build a new engine. SwanLake wraps DuckDB for service use: each session has an isolated connection, startup preloads ducklake/httpfs/aws/postgres extensions, and SWANLAKE_DUCKLAKE_INIT_SQL can inject bootstrap SQL.
4) Datalake Layer: DuckLake⌗
DuckLake is the key piece. Without it, DuckDB is mainly an excellent local analytical engine. With DuckLake, metadata and object-storage paths can be organized consistently, which makes DuckDB-based datalake services practical.
5) Operations Layer: Metrics + Status + Config⌗
Runtime metrics (latency/slow query/errors), status endpoints (/ + status.json), and env-based configuration (SWANLAKE_*) form the operational surface. This layer is what makes the system observable and manageable in production.
Observability was a first-class requirement⌗
SwanLake has a built-in status page (default :4215) plus status.json for machine consumption. It exposes:
- session counts and idle indicators,
- query/update latency stats (avg, p95, p99),
- slow query and recent error history.
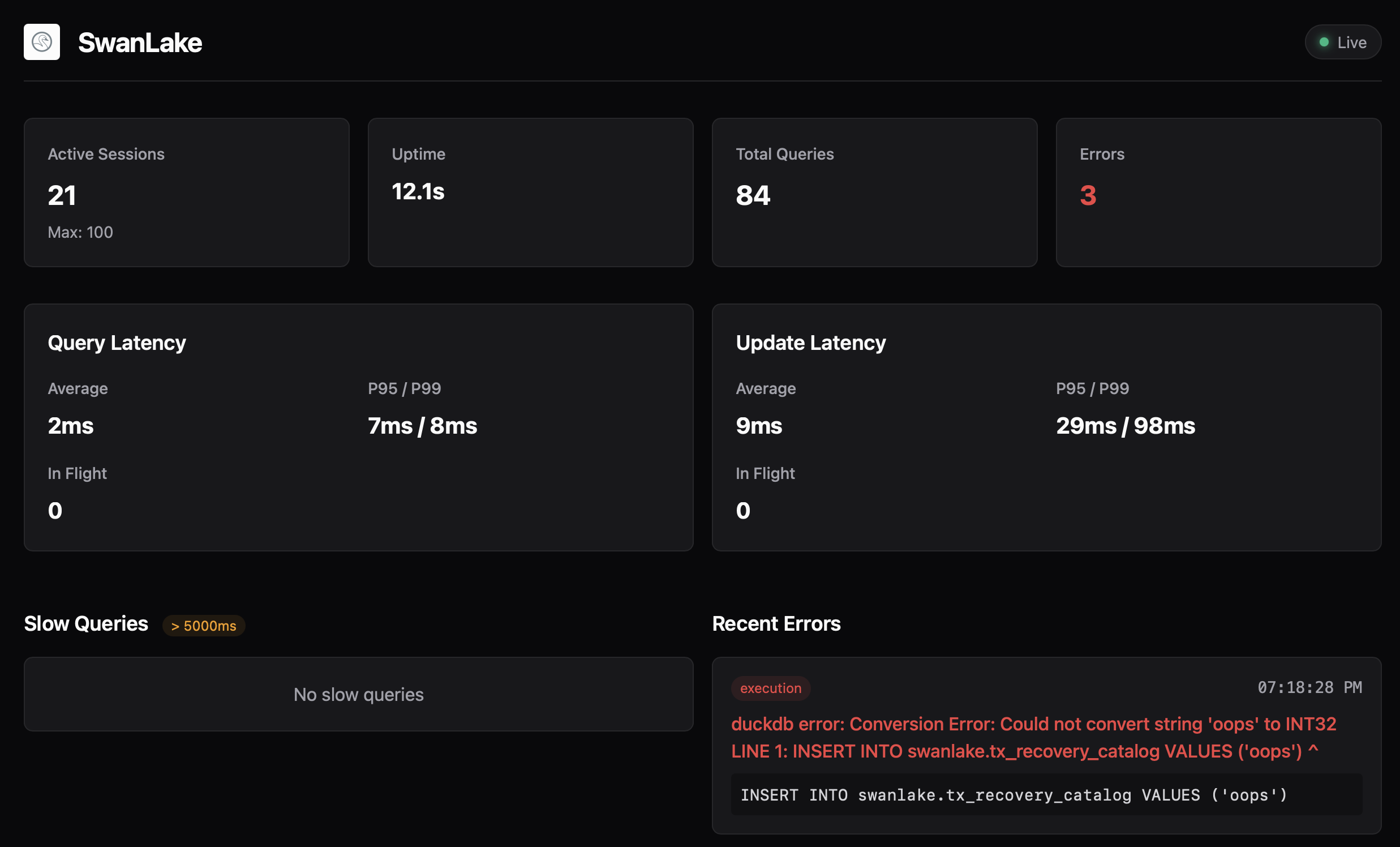
I added this because these are exactly the signals I want when debugging production behavior.
How I read the current benchmark data⌗
BENCHMARK.md (CI artifact dated 2026-02-21) includes TPCH results at SF=0.1 where postgres_local_file outperforms postgres_s3 in that run.
| Metric (SF=0.1) | postgres_local_file | postgres_s3 |
|---|---|---|
| Throughput (req/s) | 10.428 | 4.867 |
| Avg latency (ms) | 382.751 | 818.041 |
| p95 latency (ms) | 829.236 | 1904.023 |
| p99 latency (ms) | 1116.002 | 2661.619 |
This is expected directionally: object storage paths usually add more variability.
One practical point is critical here: when using S3 or other remote object storage, you should usually enable cache_httpfs, otherwise latency, especially tail latency, can become very unstable.
This is already reflected in the benchmark workflow configuration. See .github/workflows/performance.yml:
postgres_s3defaults toBENCHBASE_ENABLE_CACHE_HTTPFS=true,postgres_local_filedefaults toBENCHBASE_ENABLE_CACHE_HTTPFS=false,- the workflow input can override this behavior.
But I do not think the takeaway is “local is always better”. A better takeaway is:
- choose storage tiers based on workload shape,
- run repeated benchmarks and track variance,
- keep performance visibility continuous, not one-off.
From duckdb-rs to SwanLake⌗
For me, duckdb-rs and SwanLake are part of the same line of work.
duckdb-rs solved: how to use DuckDB elegantly inside Rust applications.
SwanLake solves: how to provide DuckDB as a shared, deployable, operable service for teams.
What I will keep working on⌗
SwanLake is still evolving. My near-term focus is:
- more production-oriented reliability and load testing,
- better performance predictability on object storage backends,
- a more consistent developer experience across server and clients.
If you used duckdb-rs before, I would love you to try SwanLake and share feedback via issues or PRs.